
Özet Çıkarımlar
10 TB veri ve saniyede 10.000 yazma isteğinde sisteminiz neden tıkanır
Dikey ölçeklemenin pratik sınırları nerede başlar?
Yazmalar neden özellikle zorlar: indeks, kilit ve disk gerçeği
Sharding ihtiyacını doğru teşhis etmek için hızlı kontrol listesi
Bu bölümün sonunda ne yapabileceksiniz?
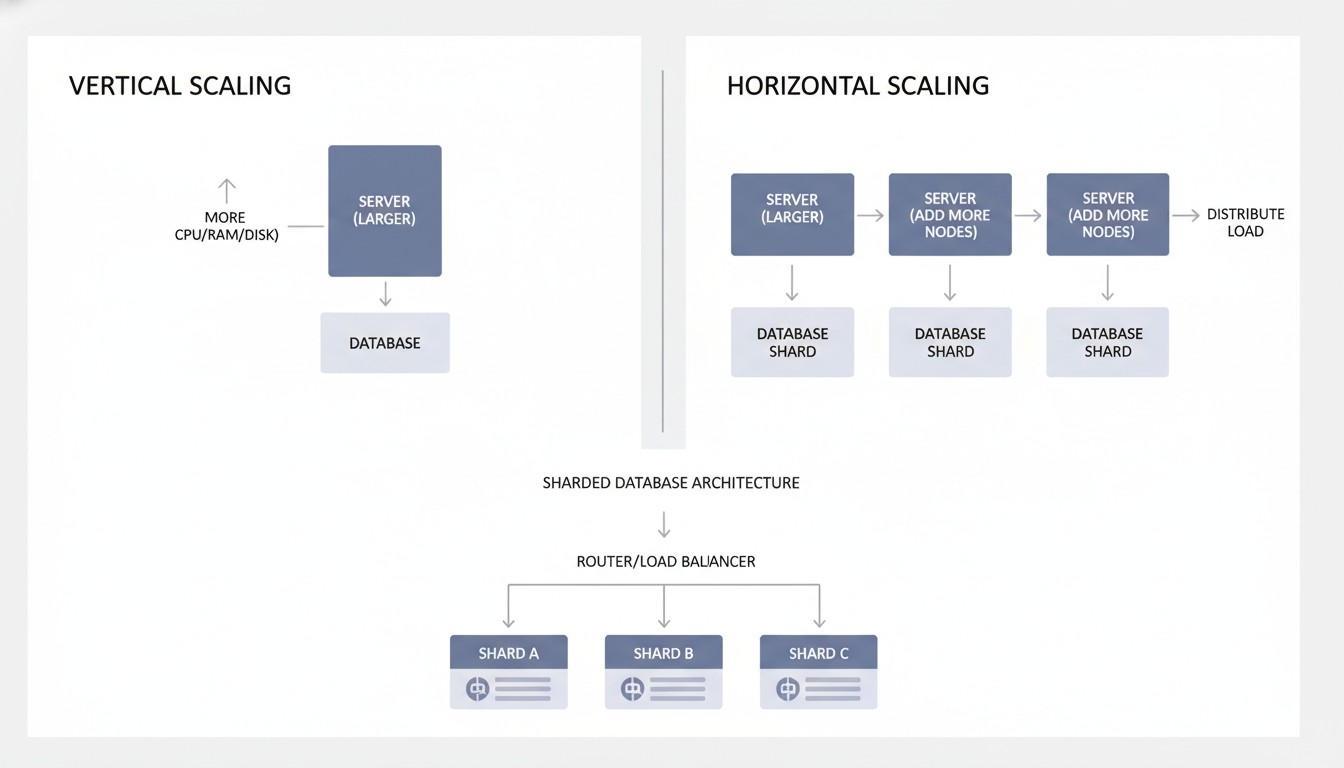
Sharding: Neyi çözer neyi çözmez?
Öncelikle, zaman ve risk harcamadan önce beklentileri belirleyin.
Shard key seçimi: performansı yükselten seçim kriterleri ve anti-patternler
Performansı taşıyan 3 seçim kriteri
Sık görülen anti-patternler ve nasıl fark edilir
Pratik kontrol soruları (toplantıda kullanılacak kısa liste)
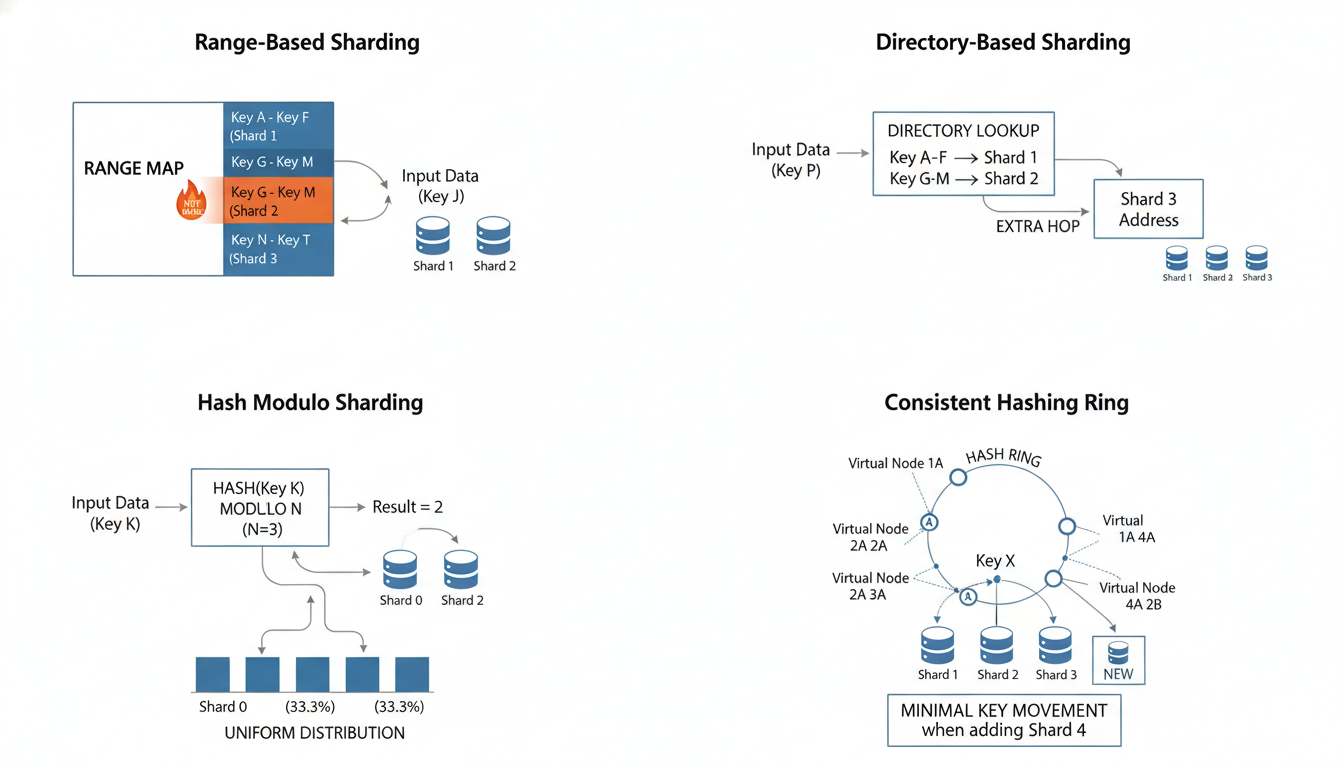
Veriyi shard’lara dağıtma stratejileri: range, directory, hash ve consistent hashing
Kapanış
Sharding hakkında en sık sorulan sorular
Sharding ile replikasyon arasındaki fark nedir, birlikte nasıl konumlanırlar?
Sharding veriyi yatay böler; kapasite ve yazma ölçeği getirir. Replikasyon aynı verinin kopyalarını tutar; okuma ve erişilebilirlik içindir. Pratikte önce shard, her shard içinde 2–3 replika yaygındır. Replikasyon shard key sorunlarını çözmez.
Cross-shard sorgularını tamamen engellemek mümkün mü, hangi durumlarda kabul edilir?
Tamamen engellemek zor. Kabul edilebilir durumlar: düşük trafikli admin raporları, batch işler, gün sonu mutabakatı. Kritik akışta tek shard hedefleyin. Kısıtlı zamanınız varsa, ana sorgular için shard-key filtre zorunluluğu koyun ve diğerlerini asenkron rapora taşıyın.
Hot key tespitini nasıl yaparım ve ne zaman yeniden shard key seçmeliyim?
Önce metriklere bakın: shard başına QPS, p95 gecikme, CPU, disk I/O, en çok yazılan anahtarlar. Loglara 1–5 dakikalık örnekleme ekleyin. Bir shard sürekli 2–3 kat yük alıyorsa hot key vardır. Fix: tuzlama, tenant bölme, ya da key’i yeniden seçme.
2PC mi saga mı: hangi iş yükünde hangisi daha doğru bir tercih olur?
2PC tek işlemde güçlü tutarlılık isterken (ör. para transferi) işe yarar ama gecikme ve kilit riski artar. Saga, servisler arası uzun akan işlerde (ör. sipariş, kargo) daha uygundur. Yaygın hata: 2PC ile her şeyi bağlamak; fix: idempotency ve telafi adımı eklemek.

Copyright © 2026
MvpAkademi, Higgs Digital Ltd (UK) tescilli markasıdır.
Created with
